
Edge Computing – Rechenleistung, wo sie gebraucht wird
Edge Computing, Smart Factory, IIoT und Big Data – alles Buzzwords die seit geraumer Zeit kursieren. Wir bei Codeatelier beschäftigen uns Tag für Tag intensiv mit diesen Themen. Cloud ist für uns nicht nur ein abstrakter Begriff, sondern unser täglich Brot. In diesem Blogpost wird erklärt, was Edge Computing ist und welche Möglichkeiten Industrial Internet of Things uns und damit auch euch bietet.
Edge im Wachstum
Der englische Begriff „Edge“ (wtl. Rand) bezeichnet in der IT den Rand beziehungsweise die äußersten Ausläufer eines Netzwerks. Dabei kann es sich um ein Mobilfunknetz, das WLAN in einer Fabrikhalle oder im übertragenen Sinne auch ein „virtuelles“ CDN (Content Delivery Network) handeln. Als Edge Nodes bezeichnet man dabei die Komponenten, die die Schnittstelle zwischen den Clients und dem Rest des Netzwerks darstellen. Auf die genannten Beispiele bezogen, wären das ein Mobilfunkmast, ein WLAN-Router und ein Cache-Server beim CDN.
Die Anzahl der Clients, die in diesen Randbereichen operieren, ist in den letzten Jahren immer mehr gewachsen. Dazu zählen nicht nur PCs, Notebooks und Smartphones, wie man sie als Verbraucher klassischerweise kennt, sondern auch sogenannte „IoT-Devices“. IoT steht für Internet der Dinge (engl. Internet of Things). Darunter fallen alle vernetzten Geräte, deren Kommunikation nicht zwangsweise auf die direkte Aktion eines Nutzers zurückzuführen ist und die auch untereinander Informationen austauschen. Dabei kann es sich um eine Wetterstation handeln, die Ihre Messdaten in die Cloud schickt oder auch um sogenannte „Smart Home Appliances“. Beispiele hierfür sind intelligente Heizungsthermostate, internetfähige Lampen oder ein smarter Kühlschrank.
Auch im industriellen Bereich nimmt die Anzahl der miteinander vernetzten Geräte immer weiter zu. Hier spricht man vom Industrial Internet of Things (IIoT). Beispiele dafür sind nicht nur einzelne Maschinen wie ein Roboterarm, sondern mittlerweile auch vollvernetzte, hochautomatisierte Produktionsstraßen, die kaum noch menschliche Interaktion benötigen. Immer mehr Unternehmen setzen auf diese sogenannten „Smart Factories“. Dort ist alles automatisiert.
Jede Maschine enthält Sensoren, die ihren Zustand und den des Werkstücks überwachen. Dies ermöglicht es zum einen intelligente Vorhersagen zu treffen, wann eine Maschine gewartet werden muss, um Produktionsausfälle durch einen Defekt zu vermeiden. Man spricht hier von „Predictive Maintenance“. Zum anderen, kann die Qualität des Werkstücks überwacht und durch Nachjustieren der Maschinen optimiert werden. Auch die einzelnen Bauteile sind mittels RFID-Tags ins System integriert und können durch den gesamten Fertigungsprozess hindurch nachverfolgt werden. Dies sorgt nicht nur dafür, dass ein Bauteil automatisiert zum Einsatzort transportiert werden kann, sondern ermöglicht es auch, den Lagerbestand zu überwachen und automatisiert zu verwalten. Geht der Vorrat eines Bauteils zur Neige, kann eine Nachschubbestellung angestoßen werden.
Big Data – Wachstumsmotor oder Show Stopper?
Nicht nur die Anzahl der vernetzen Geräte steigt stetig, sondern dementsprechend auch die Menge der übertragenen Daten. Unabhängig vom Ursprung ist das endgültige Ziel dieser Daten immer die Cloud. Dort werden sie gesammelt, analysiert und wertvolle Erkenntnisse aus ihnen gewonnen. Man spricht hier von „Big Data“.
Dies impliziert zwei technische Herausforderungen:
1. Die Daten müssen übertragen werden.
2. Die Daten müssen gespeichert werden.
Selbst bei Glasfaseranschlüssen mit Upload-Geschwindigkeiten im Gigabit-Bereich und Latenzen (Verzögerungs- oder Reaktionszeiten) im Millisekundenbereich ist es nicht möglich unbegrenzt viele Daten parallel zu übertragen. Hier kann es schnell zu Engpässen kommen. Während bei Verbrauchern noch ein umfangreiches Smart Home mit etlichen datenintensiven Geräten wie Überwachungskameras notwendig ist, um an diesen Grenzen überhaupt zu kratzen, ist man sich in der Industrie schon lange dieses Problems bewusst. Hinzu kommt, dass man im industriellen Umfeld häufig auf die zeitnahe Auswertung der gesammelten Daten angewiesen ist. Eine Verzögerung resultiert im besten Fall in zusätzlichen Kosten, weil sich zum Beispiel der Fertigungsprozess in die Länge zieht. Im schlimmsten Fall kann es aber sogar zu Sach- oder Personenschäden kommen, weil beispielsweise sicherheitsrelevante Maßnahmen zu spät eingeleitet wurden.
Beispiel: Regulierung eines Druckventils.
Auch beim Problem der Datenspeicherung sind Privatanwender eher außen vor. Diese übernimmt meist ein Dienstanbieter. Im Gegenzug profitiert er aber auch am meisten von der Auswertung der Daten. Unabhängig davon, ob es sich um eine kommerzielle oder eine industrielle Cloud handelt, kostet Speicherplatz Geld. Bei Big Data im Terrabyte- bis Exabytebereich kann das sehr schnell sehr teuer werden. Daher ist es wichtig, dass auch nur Daten gespeichert werden, aus denen man tatsächlich Nutzen ziehen kann. Aus diesem Grund müssen die Daten vor ihrer Ablage gefiltert, aufbereitet und ggf. auch zusammengefasst werden.
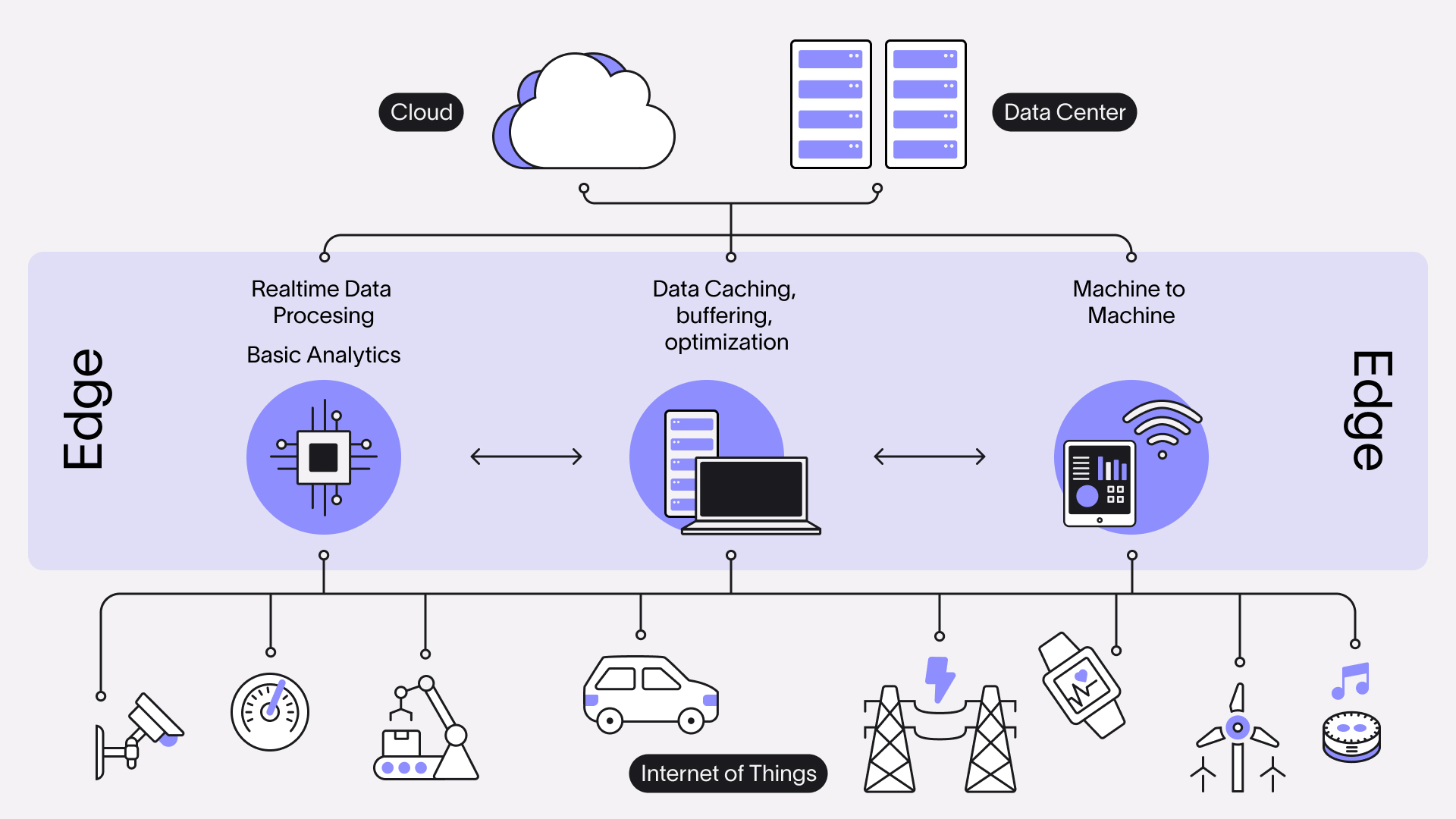
Edge Computing to the Rescue
Ein weit verbreiteter Lösungsansatz für die genannten Probleme ist Edge Computing. Wie der Name vermuten lässt, wird bei diesem Konzept Rechenleistung nicht von einem zentralen Server im eigenen Rechenzentrum oder in der Cloud bereitgestellt, sondern im Edge, also am Rand des Netzwerks, möglichst nah bei der Datenquelle. Je nach Anwendungsfall variiert die Entfernung. Bei einer Smart Factory kann beispielsweise ein einzelner Server vor Ort betrieben werden, der alle Daten vorverarbeitet und die Produktion steuert. Ein selbstfahrendes Auto hingegen muss intern die Möglichkeit haben, alle anfallenden Daten zu analysieren. Hier kann die geringste Verzögerung bei der Entscheidungsfindung katastrophale Folgen haben, weshalb eine netzwerkbasierte bzw. zentralisierte Lösung für mehrere Autos wenig Sinn ergibt. Das schließt eine Kommunikation zwischen den Autos natürlich nicht aus. Es geht sogar in noch kleinerem Maßstab: Apple hat vor kurzem bekannt gegeben, dass die Spracherkennung ihres Sprachassistenten Siri zukünftig auch auf der lokalen Hardware funktionieren soll. Auch das ist eine Art von Edge Computing.
Edge Computing hilft also Übertragungskosten und die Wartezeiten zu senken. Aber es hat nicht nur Vorteile. Durch die Dezentralisierung wird es schwieriger die Sicherheit von Hardware, Software und den Daten zu gewährleisten. Zudem wird die Wartung erschwert, da diese unter Umständen vor Ort erfolgen muss. Weitere wichtige Aspekte sind die Ausfallsicherheit und Skalierbarkeit: Bei zentralisierten Systemen in der Cloud ist es relativ einfach in kurzer Zeit einen neuen virtuellen Server bereitzustellen und den Datenverkehr im Fehlerfall umzuleiten. Beim Edge Computing muss je nach Anwendungsfall die komplette Hard- und Software redundant vorgehalten werden, um einen „Single Point of Failure“ zu vermeiden, der das gesamte System lahm legt.
Fazit
Edge Computing ist ein mächtiges Werkzeug, dessen Einsatz vor allem im Bereich der Echtzeitdatenverarbeitung sinnvoll ist. Es hilft Übertragungskosten und die Wartezeiten zu senken, sorgt aber im Gegenzug auch für neue technische Herausforderungen.